Column이 15개 있는 14만여개의 해외 기업 데이터를 임베딩 및 트레이닝 하여 커스텀 모델을 생성한 다음 이 파인튜닝한 모델을 인공지능 챗봇에 장착하여 해외 기업 데이터에 관한 질문에 최적의 답변을 해 주는 프로젝트를 수행중에 있습니다.
먼저, 전체 프로세스를 정리해 보면 대략 (1) column이 15개 있는 14만여개의 CSV 데이터를 불러와서 DB에 저장하는 것 (2) 각 column 데이터를 한 문장으로 변환하는 것, (3) 14만여개의 저장된 각 문장을 임베딩 처리하는 것, (4) 14만여개 문장을 GPT 학습을 위한 jsonl 포맷으로 변환하는 것, (5) GPT 학습시키고 커스텀 모델을 만드는 것, (6) 답변을 위한 최적의 방안을 찾는 것 정도가 될 것 같습니다.
(1) 15개 column이 있는 14만여개의 CSV 데이터를 불러와서 DB에 저장
CSV 칼럼과 매핑될 필드 값을 커스텀하는 기능, CSV 포맷을 import 하면서 필드 값에 매핑하는 기능은 워드프레스 플러그인으로 처리 가능하여 14만여개 CSV 데이터 처리 시 어려움은 없습니다. 단, 데이터 업로드에 2-3 시간 걸릴 수 있습니다.
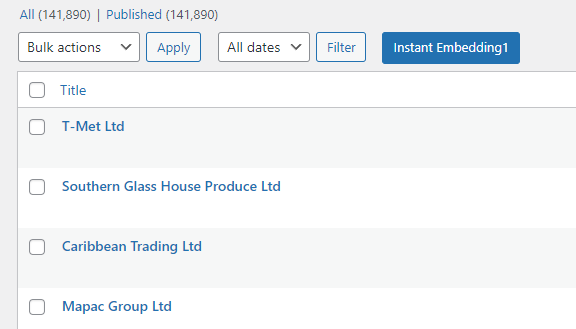
(2) 각 column 데이터를 한 문장으로 변환
15개 컬럼을 한 문장으로 변환하는 작업은 코드 작업으로 처리해야 합니다. 코드 작업이 완료된 결과 화면은 다음과 같습니다.

(3) 14만여개의 저장된 각 문장을 임베딩 처리
14만여개의 문장을 하나씩 임베딩 처리하는 데에는 상당한 노력과 시간이 들어갑니다. 그래서 좀 편하게 작업하기 위해 일부 자동화 처리 하였습니다.
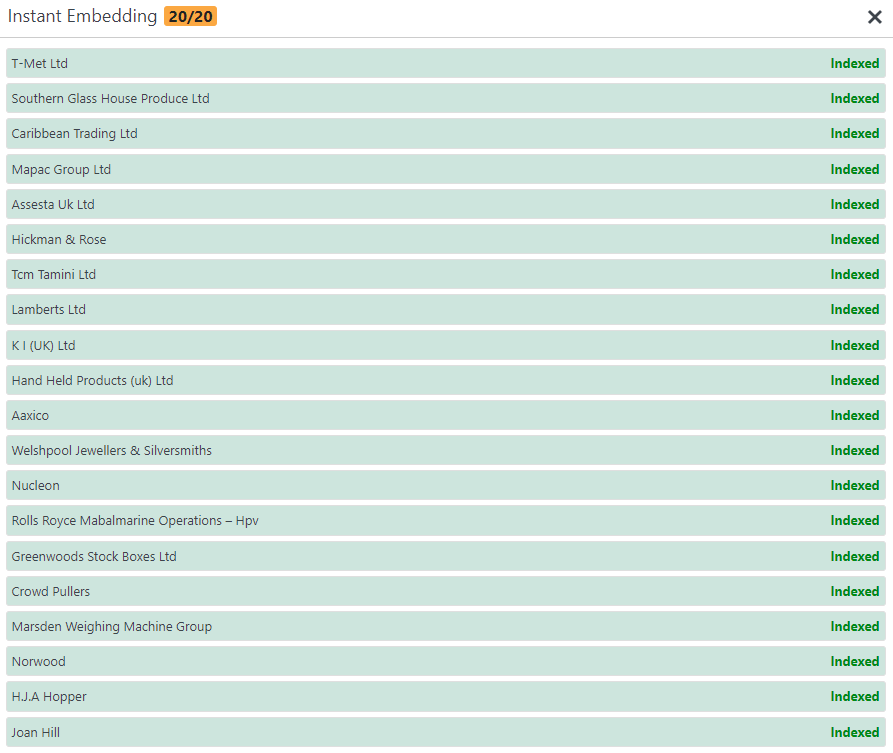
특히, 이 단계 작업에서는 워드프레스에서 커스텀 포스트 타입을 생성하여 처리하다 보니 커스텀 포스트 타입을 처리해야 하는 추가 작업이 있습니다.
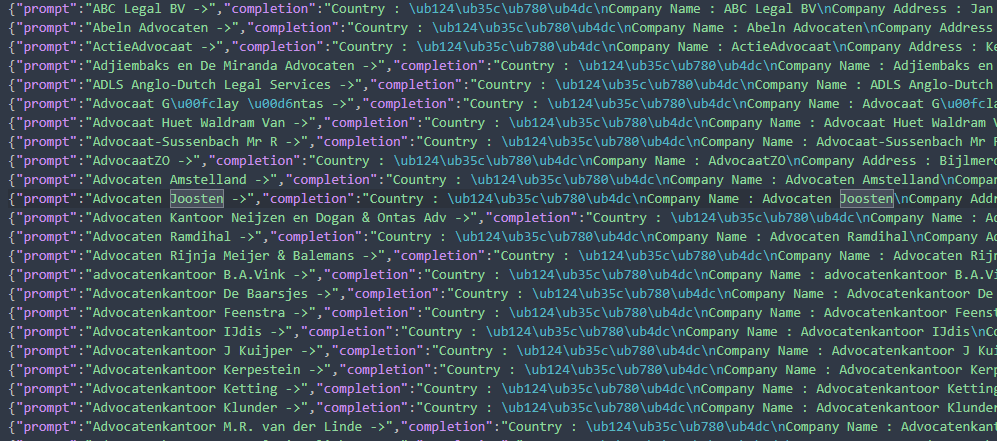
(4) 14만여개 문장을 GPT 학습을 위한 jsonl 포맷으로 변환
이 부분에 좀 어려움이 있네요. 물리적인 데이터 양이 많다 보니 자동화 처리를 해야 하는데, 이를 어떻게 처리하는 게 효과적일지 좀 고민이 되었는데, 커스텀 포스트 타입의 14만여개 데이터를 하나씩 불러와서 이를 prompt 와 completion으로 변환하는 conveter를 개발하였습니다. 변환 완료된 예는 다음과 같습니다.
다음 글에서 이어서 설명하겠습니다.